
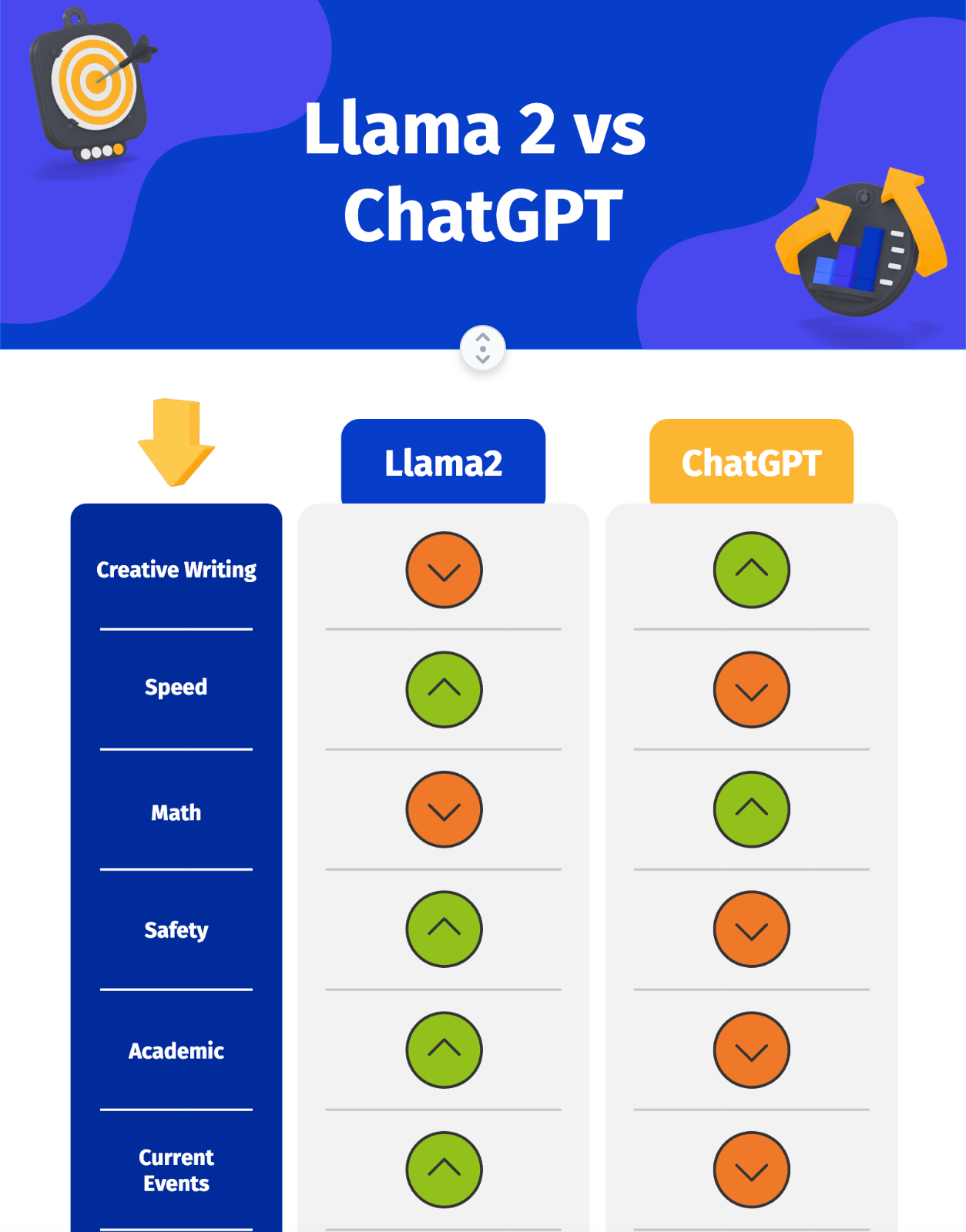
Web Llama 2 outperforms ChatGPT in most benchmarks including generating safer outputs with a higher. Web Evaluating Llama 2 and ChatGPT This section will evaluate two chatbot models. Web According to Similarweb ChatGPT has received more traffic than Llama2 in the past month with about. Web Key Differences Between Llama 2 and ChatGPT While both are large language models capable of generating human. Get ready to explore the exciting realm of AI language models as we pit two heavyweights against each. Web Both Llama 2 and ChatGPT correctly recommended to attend the emergency department and the. Web Le modèle linguistique Llama 2 est disponible avec trois tailles de paramètres différentes. Lets compare Llama 2 and ChatGPT-4 in terms of their features parameter..

Neuroflash
Whats the difference between Llama 2 7b 13b and 70b Posted August 4 2023 by zeke Llama 2 is a new open. Differences between Llama 2 models 7B 13B 70B Llama 2 7b is swift but lacks depth making it suitable for basic. Llama 2 Instruct - 7B vs 13B How good are the Llama 2 Instruct models and how significant is the difference bw 13B and 7B. Mistral 7B shines in its adaptability and performance on various benchmarks while Llama 2 13B excels in. For a holistic evaluation we assess the 7B and 13B versions of Llama 2 across the four pillars of our Evaluation. The Mistral AI team has unveiled the remarkable Mistral 7B an open-source language model with a. A few days ago the Mistral AI team released Mistral 7B which beats Llama 2 13B on all benchmarks and Llama 1 34B. Subreddit to discuss about Llama the large language model created by Meta AI..
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Alright the video above goes over the architecture of Llama 2 a comparison of Llama-2 and Llama-1 and finally a comparison of Llama-2 against other. WEB The LLaMA-2 paper describes the architecture in good detail to help data scientists recreate fine-tune the models Unlike OpenAI papers where you have to deduce it. Open Foundation and Fine-Tuned Chat Models Last updated 14 Jan 2024 Please note This post is mainly intended for my personal use. WEB Our pursuit of powerful summaries leads to the meta-llamaLlama-27b-chat-hf model a Llama2 version with 7 billion parameters However the Llama2 landscape is vast..
Stephen Medium
Fine-tune Llama 2 with DPO a guide to using the TRL librarys DPO method to fine tune Llama 2 on a specific dataset Instruction-tune Llama 2 a guide to training Llama 2 to generate instructions from. This blog-post introduces the Direct Preference Optimization DPO method which is now available in the TRL library and shows how one can fine tune the recent Llama v2 7B-parameter model on the stack. The tutorial provided a comprehensive guide on fine-tuning the LLaMA 2 model using techniques like QLoRA PEFT and SFT to overcome memory and compute limitations By leveraging Hugging Face libraries like. In this section we look at the tools available in the Hugging Face ecosystem to efficiently train Llama 2 on simple hardware and show how to fine-tune the 7B version of Llama 2 on a single NVIDIA T4 16GB -. This tutorial will use QLoRA a fine-tuning method that combines quantization and LoRA For more information about what those are and how they work see this post In this notebook we will load the large model..

Comments